


Pratique. Un cheat sheet Python très complet.
Ouch, avec l'IA, il va être de plus en plus difficile de ne pas remettre en cause ce que l'on voit, ce que l'on entend, etc.



{kind=link}
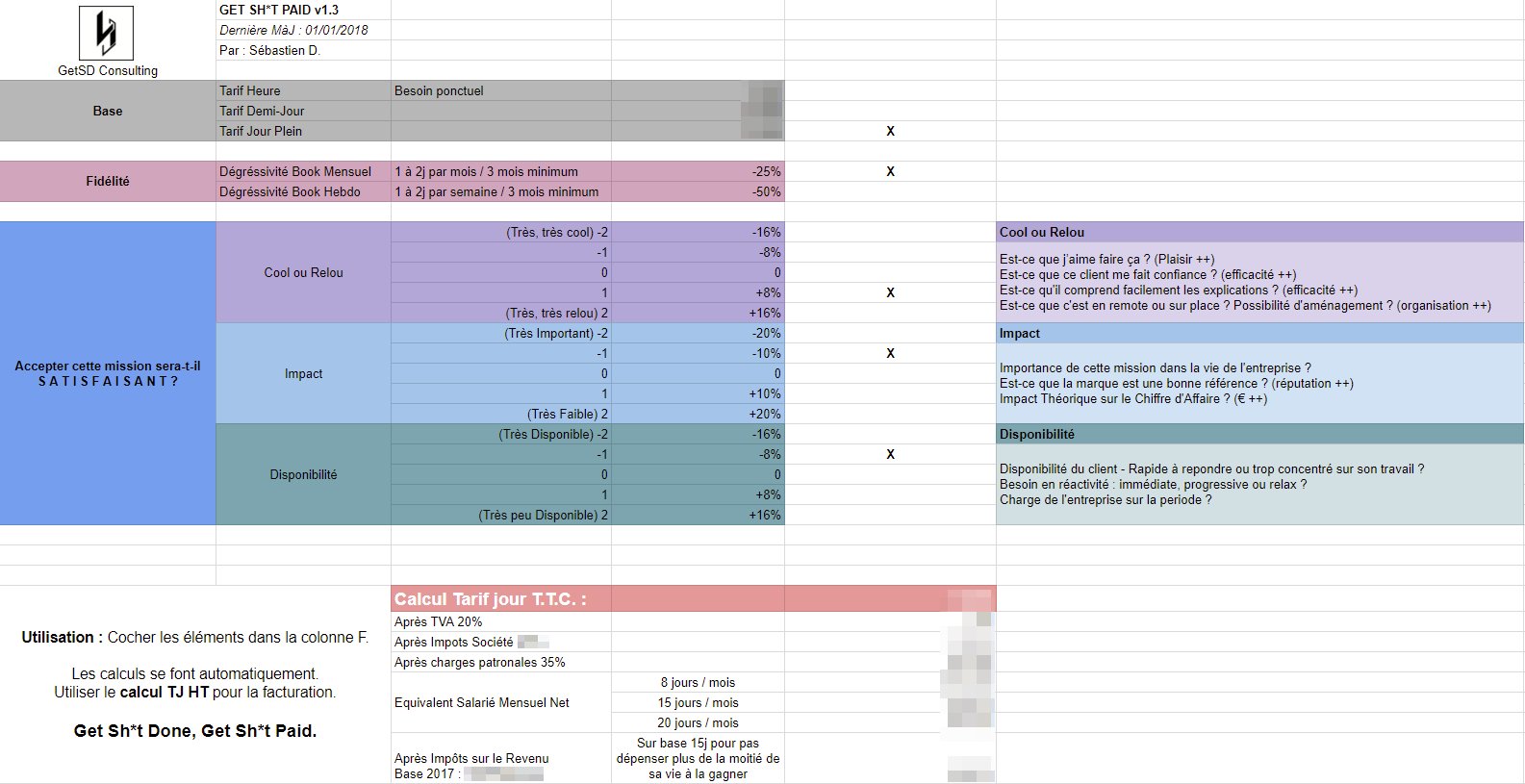
Vachement intéressant comme pratique : un freelance explique comment il prend en compte la satisfaction que lui procurera une mission pour calculer son tarif.
Le tout résumé sur une ABAC :

BTRFS est-il adapté pour les bases de données d'analyse ? Non.
Intéressant benchmarking.
Shorter: l'utilisation du copy-on-write plombe les performances de 50%, quelque soit le système de fichier qui l'emploi. Mais en plus, BTRFS, à cause de sa popote interne obtient une variabilité impressionnante dans les perfs.
Moralité ? Si on veut faire du live-snapshot sans outil couteux (ou base de données très chère qui le gère en interne) il vaut mieux utiliser un autre système de fichier COW compatible ou directement du LVM Linux.
L'avantage de ce dernier, c'est aussi de pouvoir passer en COW que lorsque nécessaire, donc d'impacter les performances la nuit quand la base est à peu près au repos.
Comment configurer sa base de données avec un SSD ?
Réponse rapide (pour InnoDB mais généralisable) :
- Sur disque rotatif (HDD) : REDO logs, BIN logs, tablespace (system ou general), buffer data
- Sur disque solide (SSD) : UNDO logs, table files (donc les table-space si on utilise separate table-space)
C'est assez dingue en soit : ça veut dire que les bases de données sont largement optimisées pour fonctionner sur disque classique, et que seule une petite partie du traitement est à accès aléatoire (donc déplaçable sur SSD).
Random i/o oriented:
- Table files (*.ibd)
- UNDO segments (ibdata)
Sequential write oriented:
- REDO log files (ib_logfile*)
- Binary log files (binlog.XXXXXX)
- Doublewrite buffer (ibdata)
- Insert buffer (ibdata)
- Slow query logs, error logs, general query logs, etc
D'ailleurs, fait intéressant dans l'article : il obtient une perf meilleure en HDD + SDD que en dual SSD. Peut-être parce que les SSD sont en bus SATA commun et que ce dernier sature, alors que ses HDD sont en bus SAS (donc séparé).
Pour aller plus loin, et configurer proprement la base :
Analyse de sentiment en R et représentation.
MOOC sur Python for Data Science, à garder sous le coude.
Rôôô, génial : une publication qui explique comment faire des graphes de dispersion qui possèdent les mêmes caractéristiques statistiques (moyennes, écart-types, corrélation) à l'aide d'algorithme de recuit simulé.
Résultat, cette image magnifique :

Oh my god, le hint de ouf : pour utiliser ses propres alias tout en faisant un sudo (sachant qu'un sudo sans option ne source ni .profile ni .bashrc etc.) il faut faire :
alias sudo='sudo 'L'utilisateur qui répond brillamment cite la doc de bash :
Aliases allow a string to be substituted for a word when it is used as the first word of a simple command. The shell maintains a list of aliases that may be set and unset with the alias and unalias builtin commands.
The first word of each simple command, if unquoted, is checked to see if it has an alias. If so, that word is replaced by the text of the alias. The characters ‘/’, ‘$’, ‘`’, ‘=’ and any of the shell metacharacters or quoting characters listed above may not appear in an alias name. The replacement text may contain any valid shell input, including shell metacharacters. The first word of the replacement text is tested for aliases, but a word that is identical to an alias being expanded is not expanded a second time. This means that one may alias ls to "ls -F", for instance, and Bash does not try to recursively expand the replacement text. If the last character of the alias value is a space or tab character, then the next command word following the alias is also checked for alias expansion.
Et pourquoi je découvre ça que maintenant moi :rage: ? Quel délire.
P.S : j'ai du lire 100 fois l'immense man bash et j'ai l'impression que j'ai tout à apprendre encore. L'outil est juste incroyablement bien pensé. Trop même.
Woké : encore du dessin / de la génération d'image assistée par du deep-learning. Cette fois, on supprime un bout de l'image, et on lui demande de compléter. Résultat juste bluffant.

Woké. Avec un bon réseau de neurones profonds, on peu désormais faire un dessin au crayon et le voir devenir une sorte de photo (c'est évidemment encore du TensorFlow).
Bon, perso j'ai essayé, mais étant très mauvais dessinateur, les résultats n'étaient pas non plus dingues (sauf à considérer ce qu'il faut de technique pour arriver ne serait-ce que là).
Je serais curieux de voir le résultat de meilleurs dessinateurs.
Très intéressant : un catalogue de Dataviz où l'on peut choisir sa représentation par fonction ou par type. Très bien !
Décidément, j'aime beaucoup ce blog / chaîne Youtube de science.
Dernière vidéo en date sur ce « crétin de cerveau » c'est-à-dire les biais cognitifs. Et cet épisode m'inspire particulièrement parce qu'il parle de probabilités et de l'impossibilité pour l'être humain de les ressentir correctement.
Regardez donc la vidéo, faites vos choix et fur et à mesure et … WTF ! J'adore :)
Une histoire de l'argent dans les films US (budgets, revenus, etc.).
Le sujet est intéressant, mais c'est surtout la visualisation qu'il faut voir. C'est magnifique, j'imagine pas le boulot pour faire tout ça.
À voir !
Balthazar Rouberol (tech lead Docker @OVH) a fait ces slides intéressantes pour introduire Docker. Sous la main.
Merci Balto.
via : https://twitter.com/brouberol/status/788843466818289664
Que se passe-t-il quand un réseau de neurones profond (DeepLearning) adapté à la vision/reconnaissance d'images est utilisé en marche arrière (en modèle générateur) ? Des chercheurs l'avaient déjà réalisé à partir de l'outil de Google.
Cette fois, c'est sur celui de Yahoo! pour la classification d'images pornographiques. Donc, ça fait une machine à créer des rêves pornographiques totalement chelous.
Les images sont dérangeantes à souhait, mais complètement SFW.
Tout ce qu'il faut pour devenir Freelance (forum de conseils, outils, recherche d'emploi, etc.)
Bien pratique !
Pas mal pratique cette page qui liste les opérations à réaliser sur Git quand on a merdé.
Wow !! Un mec a fait un travail extraordinaire à partir de Wikipedia : il a recensé les biais dits "cognitifs" dans une grande carte hiérarchique. Je suis soufflé par tant de boulot.
via : https://twitter.com/Margauxlergo/status/773184663032590337
Une bonne page pour l'optimisation générale de MySQL (dont InnoDB). Ça liste un peu toutes les variables importantes et ce qu'il faut faire.