


Pratique. Un cheat sheet Python très complet.
Ouch, avec l'IA, il va être de plus en plus difficile de ne pas remettre en cause ce que l'on voit, ce que l'on entend, etc.



{kind=link}
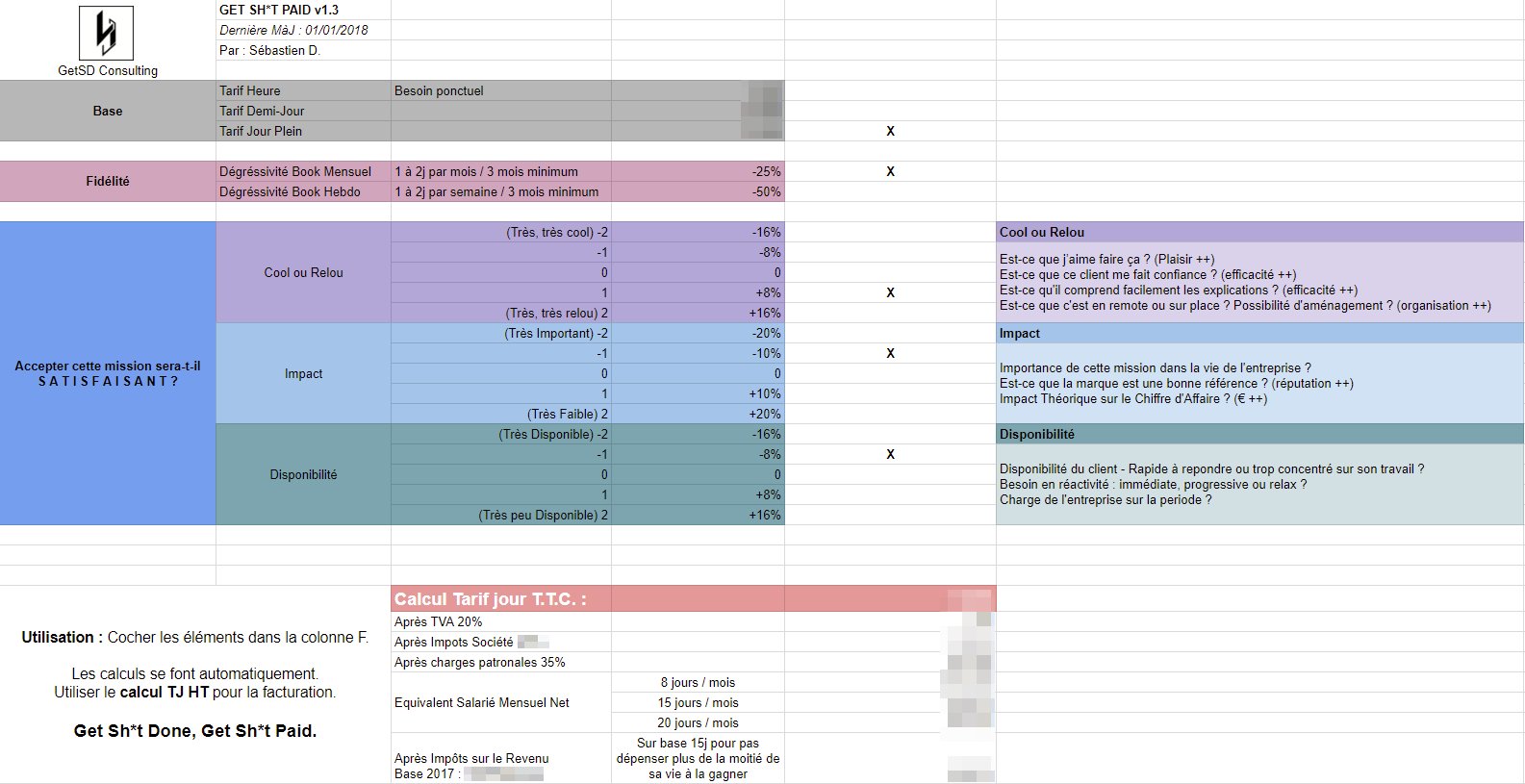
Vachement intéressant comme pratique : un freelance explique comment il prend en compte la satisfaction que lui procurera une mission pour calculer son tarif.
Le tout résumé sur une ABAC :

BTRFS est-il adapté pour les bases de données d'analyse ? Non.
Intéressant benchmarking.
Shorter: l'utilisation du copy-on-write plombe les performances de 50%, quelque soit le système de fichier qui l'emploi. Mais en plus, BTRFS, à cause de sa popote interne obtient une variabilité impressionnante dans les perfs.
Moralité ? Si on veut faire du live-snapshot sans outil couteux (ou base de données très chère qui le gère en interne) il vaut mieux utiliser un autre système de fichier COW compatible ou directement du LVM Linux.
L'avantage de ce dernier, c'est aussi de pouvoir passer en COW que lorsque nécessaire, donc d'impacter les performances la nuit quand la base est à peu près au repos.
Comment configurer sa base de données avec un SSD ?
Réponse rapide (pour InnoDB mais généralisable) :
- Sur disque rotatif (HDD) : REDO logs, BIN logs, tablespace (system ou general), buffer data
- Sur disque solide (SSD) : UNDO logs, table files (donc les table-space si on utilise separate table-space)
C'est assez dingue en soit : ça veut dire que les bases de données sont largement optimisées pour fonctionner sur disque classique, et que seule une petite partie du traitement est à accès aléatoire (donc déplaçable sur SSD).
Random i/o oriented:
- Table files (*.ibd)
- UNDO segments (ibdata)
Sequential write oriented:
- REDO log files (ib_logfile*)
- Binary log files (binlog.XXXXXX)
- Doublewrite buffer (ibdata)
- Insert buffer (ibdata)
- Slow query logs, error logs, general query logs, etc
D'ailleurs, fait intéressant dans l'article : il obtient une perf meilleure en HDD + SDD que en dual SSD. Peut-être parce que les SSD sont en bus SATA commun et que ce dernier sature, alors que ses HDD sont en bus SAS (donc séparé).
Pour aller plus loin, et configurer proprement la base :
Analyse de sentiment en R et représentation.
MOOC sur Python for Data Science, à garder sous le coude.
Rôôô, génial : une publication qui explique comment faire des graphes de dispersion qui possèdent les mêmes caractéristiques statistiques (moyennes, écart-types, corrélation) à l'aide d'algorithme de recuit simulé.
Résultat, cette image magnifique :

Oh my god, le hint de ouf : pour utiliser ses propres alias tout en faisant un sudo (sachant qu'un sudo sans option ne source ni .profile ni .bashrc etc.) il faut faire :
alias sudo='sudo 'L'utilisateur qui répond brillamment cite la doc de bash :
Aliases allow a string to be substituted for a word when it is used as the first word of a simple command. The shell maintains a list of aliases that may be set and unset with the alias and unalias builtin commands.
The first word of each simple command, if unquoted, is checked to see if it has an alias. If so, that word is replaced by the text of the alias. The characters ‘/’, ‘$’, ‘`’, ‘=’ and any of the shell metacharacters or quoting characters listed above may not appear in an alias name. The replacement text may contain any valid shell input, including shell metacharacters. The first word of the replacement text is tested for aliases, but a word that is identical to an alias being expanded is not expanded a second time. This means that one may alias ls to "ls -F", for instance, and Bash does not try to recursively expand the replacement text. If the last character of the alias value is a space or tab character, then the next command word following the alias is also checked for alias expansion.
Et pourquoi je découvre ça que maintenant moi :rage: ? Quel délire.
P.S : j'ai du lire 100 fois l'immense man bash et j'ai l'impression que j'ai tout à apprendre encore. L'outil est juste incroyablement bien pensé. Trop même.
Woké : encore du dessin / de la génération d'image assistée par du deep-learning. Cette fois, on supprime un bout de l'image, et on lui demande de compléter. Résultat juste bluffant.

Woké. Avec un bon réseau de neurones profonds, on peu désormais faire un dessin au crayon et le voir devenir une sorte de photo (c'est évidemment encore du TensorFlow).
Bon, perso j'ai essayé, mais étant très mauvais dessinateur, les résultats n'étaient pas non plus dingues (sauf à considérer ce qu'il faut de technique pour arriver ne serait-ce que là).
Je serais curieux de voir le résultat de meilleurs dessinateurs.
Très intéressant : un catalogue de Dataviz où l'on peut choisir sa représentation par fonction ou par type. Très bien !
Décidément, j'aime beaucoup ce blog / chaîne Youtube de science.
Dernière vidéo en date sur ce « crétin de cerveau » c'est-à-dire les biais cognitifs. Et cet épisode m'inspire particulièrement parce qu'il parle de probabilités et de l'impossibilité pour l'être humain de les ressentir correctement.
Regardez donc la vidéo, faites vos choix et fur et à mesure et … WTF ! J'adore :)
Une histoire de l'argent dans les films US (budgets, revenus, etc.).
Le sujet est intéressant, mais c'est surtout la visualisation qu'il faut voir. C'est magnifique, j'imagine pas le boulot pour faire tout ça.
À voir !
Balthazar Rouberol (tech lead Docker @OVH) a fait ces slides intéressantes pour introduire Docker. Sous la main.
Merci Balto.
via : https://twitter.com/brouberol/status/788843466818289664
Que se passe-t-il quand un réseau de neurones profond (DeepLearning) adapté à la vision/reconnaissance d'images est utilisé en marche arrière (en modèle générateur) ? Des chercheurs l'avaient déjà réalisé à partir de l'outil de Google.
Cette fois, c'est sur celui de Yahoo! pour la classification d'images pornographiques. Donc, ça fait une machine à créer des rêves pornographiques totalement chelous.
Les images sont dérangeantes à souhait, mais complètement SFW.
Tout ce qu'il faut pour devenir Freelance (forum de conseils, outils, recherche d'emploi, etc.)
Bien pratique !
Pas mal pratique cette page qui liste les opérations à réaliser sur Git quand on a merdé.
Wow !! Un mec a fait un travail extraordinaire à partir de Wikipedia : il a recensé les biais dits "cognitifs" dans une grande carte hiérarchique. Je suis soufflé par tant de boulot.
via : https://twitter.com/Margauxlergo/status/773184663032590337
Une bonne page pour l'optimisation générale de MySQL (dont InnoDB). Ça liste un peu toutes les variables importantes et ce qu'il faut faire.
Wow, très intéressant. Quelques bouts de codes et un peu de théorie sur la robustesse en apprentissage statistique. Voir les slides aussi, très intéressantes (bien qu'assez peu "autoporteuses" : le speech aurait été un plus)
via : https://twitter.com/dataandme/status/757648167940816896
Les différentes métriques statistiques en dessin, et pourquoi elles ne sont jamais significatives seules :
- moyenne,
- médiane,
- catégorie (modale),
- étendues (== range),
- corrélation,
- variance.
Dommage que le titre soit si mal trouvé.
Il y a toujours ce dicton qui dit "il ne faut pas croire les chiffres / les statistiques" mais c'est totalement faux. C'est l'interprétation qui est fausse ou biaisée.
Ce serait comme de dire que l'ordinateur se trompe : no, it isn't. C'est le programme qui est faux par rapport à la fonction, pas l'exécution.
via : https://twitter.com/MaliciaRogue/status/754940561304551424
Plein, plein, plein d'erreurs courantes en shell (que ce soit bash, zsh, sh, ksh, POSIX, etc.).
Et aussi un site merveilleux où on peut trouver plein de trucs utiles.
Merci à Pierre-Alain de qosgof pour ça (oui, je sais, le partage date d'aout 2013…)
Décidément, je fais bien de vider les Shaarli du patron (Seb) que j'avais mis de côté (certains datent de deux ans !)
Ici, le tableau Wikipedia des frameworks JS pour de la DataViz. Ça va bien me servir.
Cool : un tuto Docker qui semble relativement complet. Je garde sous le coude.
Excellent : un outil de deep-mining sur des images pour reproduire des styles graphiques de peintres. Ça marche relativement bien (voir très bien).
Bluffant.

John Oliver parle des études scientifiques (parfois un peu en carton) et de la façon dont elles sont communiquées au public par des journalistes imbéciles. C'est drôle et pertinent.
via : https://twitter.com/BadAstronomer/status/730071029519802369
Super vidéo sur l'effet Halo (biais cognitif qui nous laisse penser que les plus grands / plus beaux, sont plus capables).
Supers vidéo et article sur le deep-learning. En particulier les exemples sous la vidéo :)
Intéressante présentation sur TensorFlow, un outil de deep-learning de Google.
À garder sous le coude.
via : https://www.facebook.com/bdla2014/posts/1890901097803514 (Big Data Learning Association)

Oulà, j'ai tellement envie de voir ça, mais ça dur 27 minutes. Tant pis, je pose-là, à lire plus tard.
Un super dessin, assez pratique, que m'a passé un collègue pour comprendre comment s'articulent les méthodes (en particulier Agiles) les unes par rapport aux autres.
C'est franchement bien fichu, ça donne une bonne overview, et c'est drôle.
Plein de petites recettes Python, sur toute sorte de sujets. Pratique.
Owwww. Un nouveau projet Apache (Top-Level s'iouplait) pour la gestion du données. Une sorte de micro-batching, mais sans sérialisation / désérialisation. Et donc, visiblement plus rapide.
À tester donc.
Une carte montrant le déplacement des vélibs par heure à Paris. Apparemment, tout le monde commence à bosser à la même heure ! et habite à l'extérieur de Paris. En tout cas, j'aime bien ce genre de visualisation.
Génial. Une lib Python pour trainer et utiliser des réseaux de neurones. Toute sorte de réseaux. À garder absolument sous le coude.
Reparlons des boîtes noires et de l'algo magique : cette infographie illustre la problématique en terme de probas.
Même en prenant des hypothèses hyper-optimistes (du genre, l'armée développe le meilleur algo de machine-learning qui n'aie jamais existé ET la science bien de faire un saut en avant) on obtient moins de 1% des terroristes détectés et plusieurs centaines de milliers d'innocents emmerdés par la police. Shit happen.
Font chier les maths.
« Using Azure ML to Build Clickthrough Prediction Models »
Franchement, ils m'impressionnent chez Microsoft. Je les croyais mourants, inertes, plus à la page et complètement déconnectés des innovations actuelles. Et ben avec leur Azure ML, ils envoient du gros lourd.
via : https://twitter.com/FranmerMS/status/661606891760574464
Un super article pour décrire les capacités de PostgreSQL face à ses principaux concurrents (les RDBMS open-source). Beaucoup de ces features ne se retrouvent même pas dans Oracle, DB/2, …
via : https://twitter.com/brouberol/status/659466786069479424
Une comparaison de R et Python pour l'analyse de données. Ça me laisse un peu pantois : on sait déjà tous un peu ça, et les faits ne facilitent pas le choix. J'crois qu'il faut simplement apprendre les deux…
Au fait, si quelqu'un veut m'aider ?
Je n'ai pas réussi à faire correctement cette expression rationnelle :
preg_match('/^Set-Cookie:\s([^;]+).(?:;\sexpires=([^;])).*$/i', $headline, $matches)
Ce que je cherche, c'est à stocker la valeur du cookie ($headline est une ligne d'en-tête renvoyée par le serveur) mais également la date d'expiration seulement si on la trouve : expires=…
À cause du comportement glouton de .* que je n'ai pas réussi à minimiser correctement, je n'arrive pas à faire ça. Du coup, l'expression rationnelle qui est ici suppose que tout set-cookie renvoyé contiendra expires=… ce qui n'est pas la norme.
Bref, à vot' bon cœur, parce que moi j'ai abandonné.
*Indice : je pense qu'il faut utiliser des alternatives, mais je n'ai pas trouvé comment.
exemple de ligne : "Set-Cookie: SESS1121212121=454545454545; path=/; expires=Fri, 14 august 2015 GMT; domain=.mediapart.fr\r\n"
Yop,
j'ai commis ça (commit, uhuh). J'avais pas codé dans ce genre de langage depuis bien longtemps, et ça m'a pris un peu de temps, mais c'était un vrai plaisir. D'autant plus que j'avais quasi jamais fait de php et jamais utilisé les différentes lib présentes (cURL, etc.) (oui, mon travail consiste plutôt à utiliser des langages de statistiques, alors ça fait plaisir de revenir vers un truc qui a du sens).
J'ai même mis la main 5 minutes dans git/github pour faire un beau pull request. C'est-y pas merveilleux ? #fier
Je crois savoir que c'était un truc attendu (en tout cas, moi je l'attendais, so DIY). N'hésitez pas à partager vers les intéressés et faire des retours (et me féliciter :p)
Bisous.
EDIT : à propos de Regexp [à vot' bon cœur] http://foualier.gregory-thibault.com/?GCLwNQ
Je mets ça ici : le truc de Google en deeplearning, qui « produit des images » par rapport à d'autres, et par voie de ressemblance. Dans ce cas, ce sont des réseaux neuronaux multicouches qui sont utilisés.
Très bon article sur les données “molles”. Concept qui recouvre plusieurs choses : les méta-données, la psychologie, et notamment dans la mesure, etc.
Dans un monde de data, c'est important d'avoir ça en tête, parce qu'il faut sortir de la donnée stricte qui peut être hyper trompeuse.

Une autre initiation à Docker, en français cette fois.
Super.

Visualisation des déplacements des français, grâce à leurs téléphones portables. Année 2007. Génial.

Pour comprendre pas mal de choses sur Docker.
Shorter : ça ne remplace pas les VMs, chaque instance, et même chaque état possède un ID, on peut revenir en arrière, etc. Horriblement plus flexible que du Cloud VM. Mais finalement peut-être moins pratique des des gros bundles en VM pour les grosses applis pré-industrialisées.
via : https://twitter.com/brouberol/status/546421962244124673
Facebook met à disposition en open-source des outils de machine-learning ou deep-learning. Ils travaillent (évidemment) beaucoup sur le sujet actuellement.
À garder sous le coude.
via : https://twitter.com/erikbryn/status/556454800150499328
J'aime bien les décodeurs. C'est un travail sain et nécessaire. Mais qui se sent encore concerné par la vérité ?
Notamment le fameux cliché du français glandeur (qui pourtant est l'un des plus productif au monde) : http://www.lemonde.fr/les-decodeurs/article/2014/09/18/la-france-pays-ou-l-on-travaille-le-moins_4489150_4355770.html
via : https://twitter.com/romainlalanne/status/575650394161938432
Un bon résumé des manipulations, tromperies et mensonges des instituts de sondage français. Et encore, je pourrais rajouter une foule d'arguments, à la pelle.
Tiens, il me semblait l'avoir déjà publié, mais je ne le retrouve pas.
Des explications sur les notions de risque statistique, d'étude de mise sur le marché / efficacité / impactologie / etc., et du fameux problème du paradoxe de Simpson (facteur de confusion caché)
C'est vraiment très intéressant de l'expliquer comme ça : simple, efficace.
via : https://twitter.com/Dr_Stephane/status/591512248230617089
Quand même, tout ce travail qu'on fait faire gratuitement à des « passionnés » par leur boulot, ça devient emmerdant. Tout travail mérite salaire, hein.
C'est comme (pour mon métier) ces foutues plateformes qui pullulent un peu partout : Kaggle, datascience.net, le challenge SNCF. Je vous encule, m'voyez-vous ? Oui, je vous encule. Mes compétences m'ont coûté des années d'études, alors fuck.
Voir aussi : http://foualier.gregory-thibault.com/?u_Colg
via : https://twitter.com/Bouletcorp/status/597760146308141058
Article FRANCHEMENT intéressant sur le théorème CAP, qui est souvent mal compris. Il m'a ouvert les yeux alors que je pensais le maitriser.
Ceci dit, les conclusions restent un peu les mêmes, mais ce qui est entendu dans les différents concepts est différent de ce que j'avais compris intuitivement (surtout sur Partition Tolerance)
Pour rappel, le théorème CAP parle de système distribués et de scalabilité :
« Dans un système distribué (reposant sur des données partagées) vous ne pouvez conserver que deux des trois propriétés suivantes :
- [en:Consistency] Consistence ;
- [en:Availability] Disponibilité ;
- [en:Partition Tolerance] Résistance au partitionnement »
Shorter : la dernière propriété n'indique pas que le système est distribué (c'est H0, l'hypothèse de base) mais l'état d'un système distribué dans lequel certains nœuds deviennent séparés (par coupure réseau, serveur en panne, etc.) d'autres nœuds. D'où l'existence de "partitions"
Finalement, ce théorème (formellement Brewer' Theorem) indique que, dans un système distribué, en cas de partionnement, il faut choisir la stratégie transactionnelle vis-à-vis des clients :
- soit refuser de répondre pour ne pas donner une réponse incohérente ou corrompre les données ;
- soit accepter de corrompre des données (éventuellement temporairement) en écriture ou renvoyer des données anciennes (inconsistantes).
Une dernière notion enfin.
Maintenir soit A soit C est élitiste, et en pratique on peut trouver un continuum de stratégies. D'où les notions de :
- [en:Yield] Rendement : c'est le pourcentage de requêtes qui seront complètement (completness + correctness) exécutées ;
- [en:Harvest] Moisson : c'est la proportion de données complètes traitées sur une requête.
C'est très intéressant de travailler avec ces deux notions, notamment pour décrire des SLA. Parce que, par exemple, le "uptime" ne reflète pas vraiment la garantie offerte : les coupures lors des creux n'ont pas le même impact que lors des pics.
Pas con : pour mesurer la popularité de différents outils en entreprise, ces gens ont mesuré sur des plateformes d'offre d'emploi les occurrences des différents noms (en les débarrassant des ambiguïtés)
Intéressant.
Le paradoxe de Braess vachement bien expliqué.
Ça va certainement me servir.
10 points d'analyse statistique à respecter. Intéressant.